Moving to GraphQL

At Article, we recently introduced GraphQL as part of the new technology stack. There are many reasons and discussions behind that decision and we think it is the right time to do so.
Old Stack
Article has always been mainly using Java for all of our applications and mostly using Vue for the frontend. There is a controller for every page and dedicated RESTful API endpoints for those pages. As time progresses and we have more engineers on board, the limitations become more obvious everyday.
It is not immediately clear what parameters and what response I will expect after calling this endpoint. This is especially confusing when we have state management implementation that initializes the states directly from the output of this endpoint. We start having these magical and mysterious states flowing around in our app and nobody knows where they come from. To know what response we can get, we either test them in Postman or read the backend code. It adds overhead in engineers and they can't get started quickly.
Secondly, we often either add more data into existing endpoint or create new ones for that specific UI feature. For instance maybe we have POJOs that represent these data and these are shared with other endpoints. Endpoint B needs this data so we update that POJO even though Endpoint A doesn't need them at all. At the end, our customers are paying for the network and performance for stuffs they don't need at all.
As we have more and more services and interests in exploring new technology stack, this is a good time to see how we can tackle these issues.
Enter GraphQL, what is it though?
GraphQL is a standard developed out of the need to tackle the pain points described similarly before. Facebook saw their need to move to mobile and they first needed to support one of the most complicated features: Newsfeed. There were many challenges in building the mobile app and also saw the way they were doing things were not scalable and would result in very bad user experience. And then GraphQL was born.
GraphQL is, simply put, a way for the clients to fetch data from the servers. Yes we already have something like this called RESTful API that you can fetch as previously mentioned. GraphQL fixes some of the problems that traditional RESTful APIs have. Here are the major components of a GraphQL server.
Schemas
A schema for a product could be like:
type Product {
id: ID!
title: String!
skuNo: String!
price: Int
}Looking at this alone we know a lot of informations about this Product schema: what properties it contains, what their types are and some of them cannot be null while price can be null.
A query that queries for product in GraphQL may be:
query Product($id: ID!) {
product(id: $id) {
title
skuNo
price
}
}And the response would look like:
{
"data": {
"product": {
"title": "Beautiful Sofa",
"skuNo": "SKU001",
"price": 2000
}
}
}As you can see the response is exactly what the query describes. This takes away the code guessing time during development. What GraphQL also allows us to do is we can choose what to include in the query. For example if this piece of UI component doesn't need price then simply don't query for price. It keeps your request lean and your user doesn't pay for the extra information that is not necessary.
Having a schema like this is very beneficial so engineers know what they are working with and it serves as a self-explanatory documentation. If you are using Apollo, it has a Playground that you can check your schemas, queries, and such.
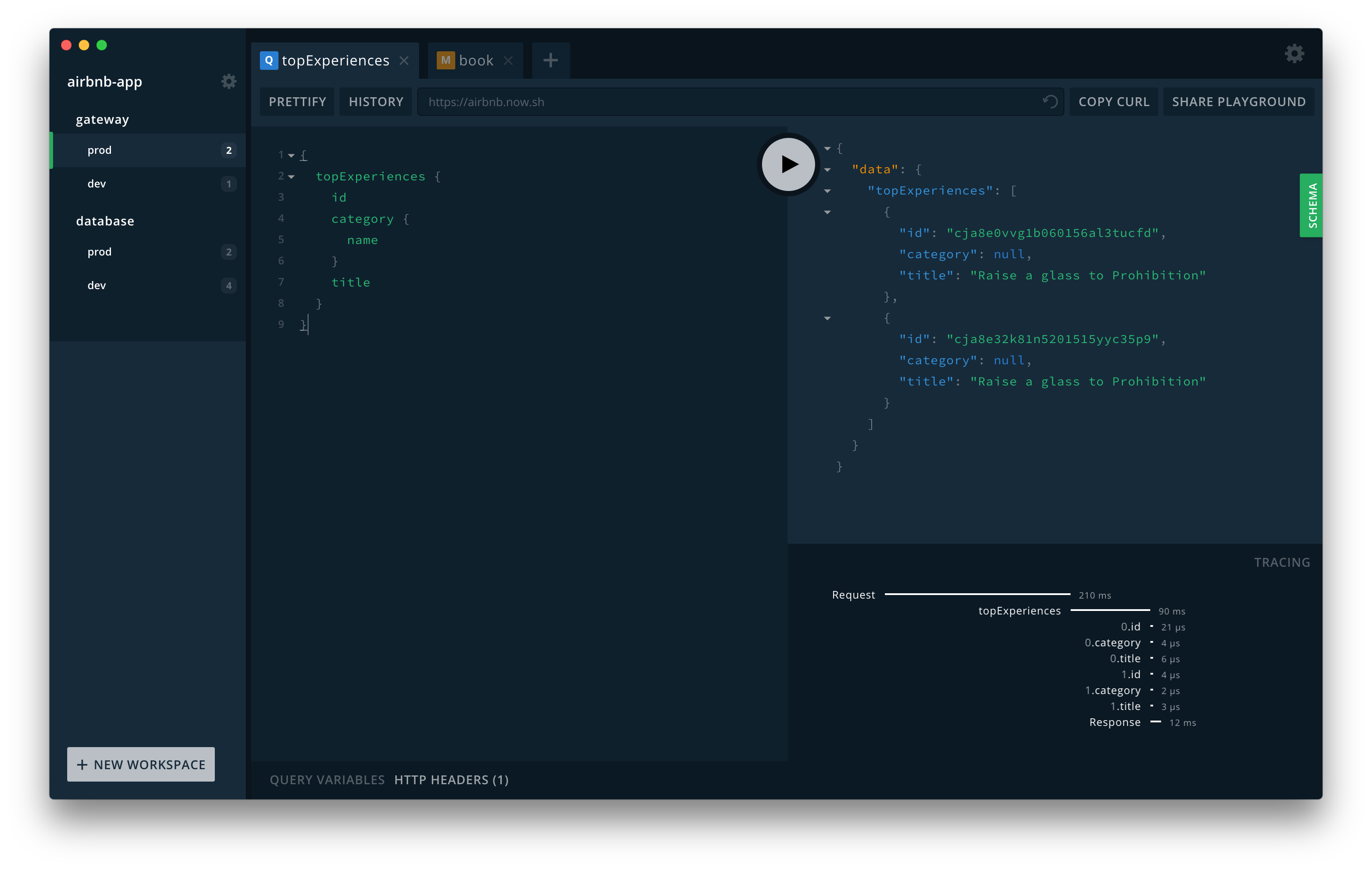
Resolvers
Resolver is how GraphQL knows when which query is run then where it needs to request the data.
export default {
Query: {
product: (_, { id }, { dataSources }) => {
return dataSources.productSource.getProduct({ id });
},
}
}The code snippet above is an example of when the product query runs, it would get the requested data from productSource. Resolver is essentially just mapping our query to where it should get data from. If you have sub-query, resolver will automatically map that for you. For example, if price should be retrieved from another service then resolver will take care of that for you.
Data Sources
This is just a file that actually does the request for you. After resolver maps the query to your data sources, you will need to send the necessary fetch call to your services. Actually it can be a database query, an AJAX request, a gRPC request, or just returns a simple JSON data.
Caching
GraphQL by nature is a POST request. This makes caching a bit difficult as we don't have a unique URL anymore that you can cache with Redis or even CDN. Fortunately, different library implementations offer different caching mechanism. Take Apollo as an example, it offers multiple ways that we can use to implement caching.
GET Request
This is probably the most straight forward to implement. When creating an Apollo client in your frontend app, you would often use apollo-link-http to define the URI of your GraphQL server, header, or authentication related setup. You can also set useGETForQueries to true so it uses GET when sending queries. But it will still use POST to send mutations.
In-Memory Cache
By default, Apollo client tries to save as many roundtrips as possible and it includes caching previous result of the same query. You can also update the cache if your app happens to post updates to certain data.
Apollo Persisted Queries
This is the Apollo's solution that incorporates GET request, browser cache, and enabling CDN on these queries. The basic idea is client would now send a hashed version of the query and if Apollo server has seen such query before then it will return the data. However if Apollo server doesn't recognize the hash then it will ask Apollo client to resend the query but in full length. Apollo server will save that query with its hashed form in addition to fulfilling that query for the client. You can check out the official documentation for Automatic Persisted Query.
Stuffs I haven't figured out
I'm not sure what other companies do in terms of dividing the work. Currently our backend engineers are responsible for the internal services and our team has more frontend engineers so GraphQL server naturally becomes frontend engineers' realms. It does increase the workload of a frontend engineer since previously this kind of work would be part of endpoint creation. The experience so far is far from smooth. Some reasons I can think of:
- Not familiar with service-to-service communication yet, especially with gRPC and protobuf contracts
- Sometimes having hard time deciding what schema should look like
- Organization and maintenance in GraphQL server hasn't been fully estblished
The first 2 points should iron out themselves as we keep developing for it and will lead us to how we should solve the 3rd point.
The other thing is if we should have one giant GraphQL server for both public and internal applications or separate them. Right now we are at the experimenting stage to see if GraphQL works for the public site and so far it is working out pretty well. Even if we are pushing this to internal apps, after talking to other engineers, we think it's probably best to separate them even though they may be deal with the same data. This should give us more and finer controls on authorization and authentication details. Furthermore, because the gRPC contracts are already established, other teams or apps can read or write day in whatever technologies they wish to use.
If you find it helpful, please do me a favor and share with other people by tweeting this post so I can know who's interested in GraphQL.